UK Healthcare Contact Centers move to secure, agile cloud platforms with MaxContact
MaxContact were selected for their true cloud elastic scalable offerings, secure remote homeworker connectivity and flexible contracts.
MaxContact have announced that they have moved four UK contact centres amassing to nearly 2,500 contact center agents to work remotely from home using the MaxContact platform, in response to increased call volumes and capacity requirements due to the COVID-19 pandemic. The rapid deployment and on-boarding of two new centres along with elastic expansion of two existing clients provided the ease and flexibility required for immediate deployment of such vital services.
Further emphasising the agility and convince true cloud service providers can offer, MaxContact provided all 4 centres within 48 hours to its clients, all working from home and including training and materials to the two new customers. MaxContact continual success as a disrupter to the industry was emphasised further by the speed and security the system offers in order to pass the stringent criteria for healthcare campaign.
“The providers perform critical contact centre services for the COVID-19 related calls, this critical service needs to be robust, reliable and secure for its centres” said Ben Booth CEO, MaxContact.” This, along with other Covid-19 campaigns we have onboarded during this time makes us proud. It shows how far we have come as a company in such a short space of time, we have been chosen by four separate centres and showing we can meet the demands of such rapid, agile and robust solutions required to help with the Covid-19 crisis”, Pat Ryan – MBA Group.
“Working with MaxContact we were able to get the system up and running, staff and agents trained and all working from home. The whole process and speed of delivery, with the ability scale so quickly was of great benfit to us. We simply wouldn’t have been able to onboard the campaign so fast if it was not for MaxContact”
“More and more companies are seeing the benefit of true cloud applications, being able to adapt to business needs and working with companies that can provide flexibility to scale up and scale down in their contracts as well as their service” said Ben Booth
Contact Centres are migrating to the cloud, a transition that looks only to be increasing, MaxContact are still operating at 100% capacity and seeing an uplift in opportunities across the robust, secure and agile contact centre marketplace. Secure homeworking has inevitably played a huge roll in this, along with the flexibility that cloud offers and suppliers like MaxContact will only continue to thrive in such a marketspace.
Analysts are predicting a significant growth in this sector with companies pulling forward plans for migration for business continuity and embracing home working environments that have been positive.
MaxContact is customer engagement software that drives impact, conversions, and smarter customer experiences. Find out more about us.
(() => {
const run = () => {
const rich = document.querySelector('#rich-text');
const toc = document.querySelector('#toc');
if (!rich || !toc) return;
const headings = rich.querySelectorAll('h2');
if (!headings.length) {
toc.style.display = 'none';
return;
}
const slugCounts = Object.create(null);
const slugify = (str) => {
const base = (str || '')
.trim()
.toLowerCase()
.normalize('NFD').replace(/[\u0300-\u036f]/g, '')
.replace(/[^a-z0-9\s-]/g, '')
.replace(/\s+/g, '-')
.replace(/-+/g, '-');
const n = (slugCounts[base] = (slugCounts[base] || 0) + 1);
return base ? (n > 1 ? `${base}-${n}` : base) : `section-${n}`;
};
// Build TOC off-DOM
const frag = document.createDocumentFragment();
for (let i = 0; i < headings.length; i++) {
const h = headings[i];
const text = (h.textContent || '').trim() || `Section ${i + 1}`;
if (!h.id) h.id = slugify(text);
const a = document.createElement('a');
a.href = `#${h.id}`;
a.className = 'content_link is-secondary';
a.dataset.target = h.id;
a.setAttribute('aria-label', text);
const p = document.createElement('p');
p.className = 'text-size-small';
p.textContent = text;
a.appendChild(p);
frag.appendChild(a);
}
// Single DOM update
toc.innerHTML = '';
toc.appendChild(frag);
toc.addEventListener('click', (e) => {
const link = e.target.closest('a.content_link[href^="#"]');
if (!link) return;
e.preventDefault();
const id = link.getAttribute('href').slice(1);
const target = document.getElementById(id);
if (!target) return;
// Only compute layout once
const targetTop = target.getBoundingClientRect().top + window.scrollY;
const finalY = targetTop - 150;
window.scrollTo({ top: finalY, behavior: 'smooth' });
history.replaceState(null, '', `#${id}`);
}, { passive: false });
};
// Webflow-safe “run after everything is ready”
if (window.Webflow && Webflow.push) {
Webflow.push(() => requestAnimationFrame(run));
} else {
document.addEventListener('DOMContentLoaded', () => requestAnimationFrame(run));
}
})();
related articles
you might also like
Our articles and industry insights give you expert perspectives, practical strategies, and the latest trends to help your business connect smarter and perform better.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
Quality assurance in a call centre is the process of monitoring, evaluating, and improving agent interactions to ensure consistent customer experience and performance standards. All contact centres have a QA process. But most struggle to drive change from the data it provides.
For years, manual QA was the only option, and for many contact centres it still is. Supervisors sample a handful of calls, score them against a checklist and then file the results. Roughly 5% of interactions get reviewed on average. And then any feedback is given to agents days later (if at all).
It was never a great system. But as interaction volumes rise, agent workloads increase, and 42% of customers say they'll switch providers after a single poor experience, the cost of that insight-to-action gap is getting harder to absorb.
This guide covers how to make the shift from using QA as a monitoring exercise to using it as a driver of performance with AI-powered QA software.
You're monitoring quality. But are you actually improving it?
Knowing how to improve quality assurance in a call centre starts with an honest question: is your QA process actually producing change, or just producing data?
Traditional QA has a lag problem built in. A call happens and a supervisor reviews it days later. Feedback reaches the agent at a point where they've had dozens of conversations since the one that’s been reviewed. The connection between the behaviour and the coaching is weak, and the window for meaningful learning has already closed.
There's also the sampling issue. Manual QA typically covers around 5% of interactions.
“Leaders want answers, but those answers sit behind small QA samples, anecdotal feedback, and performance dashboards that only tell part of the story.” Connor Bowler, Principal Product Manager at MaxContact
The result is stark: manual QA gives you a story about some of your calls while an AI-powered platform gives you the truth about all of them.
Stop treating QA as an audit. Start treating it as a coaching tool.
Improving quality assurance starts with how you think about the QA function. It’s not an audit, but rather a coaching engine.
Approach QA with an audit mindset, and you’ll get reports. Approach QA with a coaching mindset, and you’ll get improvement. Contact centres that use QA to drive real behaviour change tend to do three things differently:
What They Do
Why It Works
Close the feedback loop fast
Feedback delivered within 24 hours lands harder. Agents have context, they remember the call, and the learning is concrete rather than abstract.
Make QA data visible to agents, not managers only
When agents can see their own scores and track their own trends, QA becomes something they're engaged with rather than something that's done to them. That ownership is where improvement starts.
Coach patterns, not just incidents
A single low-scoring call is an incident. Five with the same failure point is a pattern. Coaching patterns is where QA data creates lasting change.
As AI handles monitoring and scoring at scale, QA teams move away from manual call reviews and closer to coaching, analysis, and performance design; a more valuable role, and a more sustainable one.
It's a shift some organisations are already making.
The ICX Use Case
ICX, a customer engagement provider for brands including Nissan, Suzuki, and Stellantis, replaced manual call reviews with MaxContact's Conversation Analytics platform. Quality assessors moved from repeated audio replays to transcript-based reviews, with AI-powered search surfacing compliance issues, objection patterns, and coaching opportunities across every interaction. Training is now built directly from sentiment and objection data, feeding into one-to-ones and agent development.
Call centre quality assurance metrics: What they're actually telling you
Once you've made the shift from audit to coaching mindset, the next question is: what is your QA data actually telling you?
The most common scorecard measures script adherence, handling time, first call resolution, CSAT, and compliance markers. All of these are valid, but they can mislead if you're drawing conclusions from a 5% sample. The same metrics applied across 100% of interactions tell a very different story.
A few principles that make QA data more actionable:
1. Work out whether you've got a data problem or a coaching problem.
An agent who consistently mis-dispositions calls might not need coaching, they might need better data or a clearer process. An agent whose sentiment scores drop in the last hour of every shift has a different problem entirely. QA data is most valuable when it helps you tell the difference.
2. Don't look at scores in isolation. Connect them to outcomes instead.
A call that scores well on process but ends in a complaint tells you the agent followed the script and still got it wrong. Map your QA scores against CSAT, NPS, or complaint rates to find out which quality indicators actually predict good outcomes and which ones are just measuring process-following.
3. Track how quickly agents improve after coaching.
The rate of improvement following a coaching session is more useful than the score itself. If coaching isn't producing measurable change within a defined window, perhaps it’s the approach that needs to change, not just the agent's behaviour.
4. Use sentiment data to find what scores can't show you.
Scores tell you what happened procedurally. Sentiment analysis tells you how the customer felt at the start of the call, at the point of objection, and at sign-off. The gap between a high compliance score and a negative end sentiment is often where the most valuable coaching insight sits.
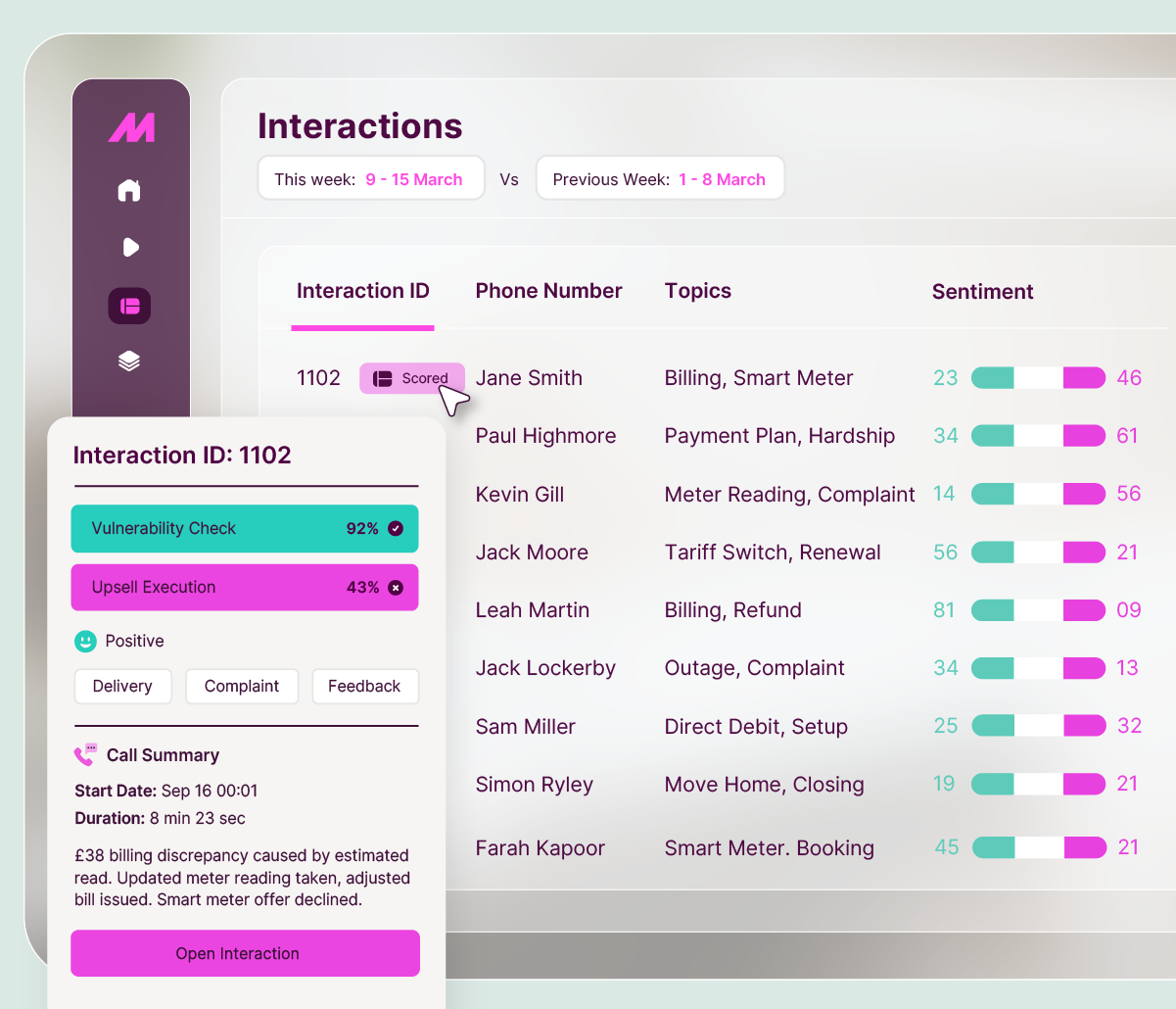
MaxContact's Auto QA applies customisable scorecards consistently across every selected interaction, including auto-fail criteria for non-negotiable standards, and surfaces sentiment alongside compliance scoring in a single view. QA managers spend less time manually reviewing calls and more time acting on what the data reveals.
Auto QA Score Card
The difference between feedback that lands and feedback that doesn't
Call centre quality monitoring best practices all point to the same conclusion: data doesn't change behaviour. Coaching does.
Specific beats general, every time. "You need to listen more actively" isn't actionable. "On this call at 2:34, the customer mentioned they'd been waiting three weeks and you moved on without acknowledging it. Here's what it sounds like when it's handled well" is constructive, actionable feedback. .
Frequency matters more than depth. Regular short coaching sessions (ten minutes a week focused on one call or one skill) tend to produce better outcomes than monthly deep-dives. Behaviour change is cumulative.
Self-review builds ownership. Agents who listen back to their own calls and score themselves before a coaching session arrive with more self-awareness and more investment in the gaps. The manager is coaching, not judging.
Use your best calls as teaching tools. Sharing anonymised examples of top-performing interactions gives the whole team a concrete standard to aim for. Not a number. A behaviour.
Data from MaxContact's Conversation Analytics platform drawn from over 700,000 objections across a six-month period, shows agents successfully overcome just 39% of objections, while 61% remain unresolved. The most challenging category is need objections ("not interested", "no immediate need"), which represent 46% of all objections but carry the lowest conversion rate. That's a pattern, and it needs a pattern-level response.
For BPOs like ICX, managing quality assurance across multiple client accounts at scale, running separate manual processes for each campaign simply isn't viable. "Anything that helps us connect to more of the conversations, especially given the volume we handle, is incredibly valuable. The team does a fantastic job, but no one can review everything manually. With Conversation Analytics, we can proactively support our agents and maintain complete oversight, so we never miss a critical moment or insight," said Sarah Franks, Call Centre Manager at ICX.
The hidden reason your QA findings never make it to the coaching conversation
There's a practical barrier between QA insight and coaching action that doesn't get talked about enough: post-call admin.
After every interaction, agents log outcomes, complete call notes, update CRM records, and prepare for the next contact. In high-volume environments, where over 52% of contact centre leaders report agent workloads have increased year-on-year, that wrap-up time absorbs the space that could go into engaging with coaching materials or reviewing their own performance data.
When agents are constantly catching up on admin, QA becomes something that happens to them in scheduled sessions, not something they engage with actively. The feedback loop gets longer. The shift from "QA as audit" to "QA as improvement" stalls.
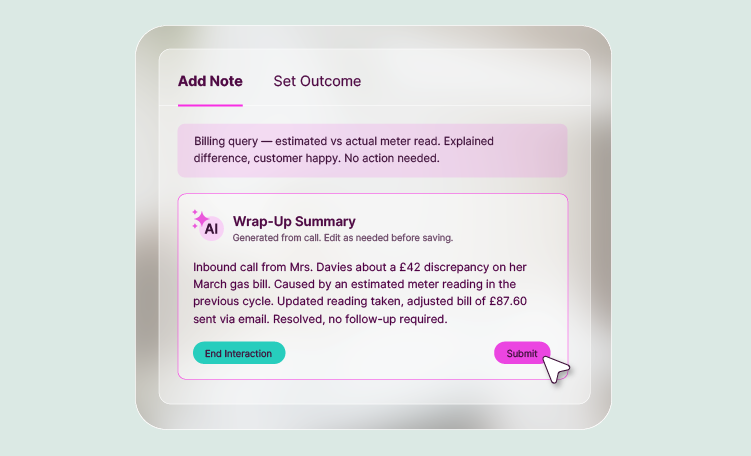
Agent Wrap-Up Summary changes this directly. By automatically capturing call summaries, key outcomes, sentiment, topics, and follow-up actions at the point of wrap, it creates a consistent record for every interaction without adding work for the agent. That frees up the time and headspace to engage with performance data in real time.
What better QA actually means for your bottom line
For contact centre leaders asking how to improve quality scores in their call centre, the answer comes down to this: quality improvement has to show up in numbers the business cares about.
For BPOs, that means client retention. Clients expect their customers to be handled to a defined standard; when quality slips, renewals are at risk. With agent attrition running at 31% across the industry, AI-powered QA becomes even more valuable. New agents can be held to the same standard from day one, without relying on institutional knowledge that walks out the door.
For financial services and insurance contact centres, the case is just as direct. Agents who handle complaints well, identify vulnerability accurately, and resolve queries first time produce better CSAT, fewer escalations, and stronger retention. With first call resolution rates dropping from 43% to 37% year-on-year, the contact centres that reverse that trend through better coaching protect both customer relationships and commercial performance.
Either way, QA only delivers value if it produces measurable change, closing the loop between monitoring, coaching, and results, consistently and at pace.
How to make all of this work when you're dealing with real call volumes
The barrier has always been operational: the volume of calls, the limits of manual review, and the admin overhead that eats into coaching time.
The contact centres that improve quality consistently aren't doing something fundamentally different. They've just stopped treating QA as something that happens after the call and started building it into how the operation runs; faster feedback, visible data, coaching that's based on patterns rather than incidents.
At the volumes most contact centres are dealing with, that only works if the infrastructure supports it. AI-powered QA removes the manual overhead that makes it impractical, covering every interaction, surfacing what matters, and giving agents and managers the time to actually act on what the data shows.
If your QA process is still generating reports instead of results, it's time to change how it works. See how MaxContact's Auto QA and Agent Wrap-Up Summary turn insight into action.
Blog
5 min read
MaxContact named one of the UK's most thriving companies to work for
We're proud to announce that MaxContact has been named a winner of the Culture 100 Awards 2026, recognising us as one of the top 100 growing companies in the UK with a genuinely people-first working environment.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
The Culture 100 Awards, run by Maya, evaluate thousands of companies across more than 22 industry sectors. What makes this recognition different is how it's determined: not by self-reported data, but by anonymous sentiment surveys and open-ended responses from employees across participating organisations. Companies are assessed on verified employee benchmarks - the kind designed to uncover how people actually feel about where they work, not just how a business wants to present itself. For us, that's exactly what makes it meaningful.
As a team of around 70 people, we've grown steadily as demand for cloud-based contact centre and engagement technology has increased, and we're thrilled to have been selected for our commitment to building an environment that holds our people as a genuine competitve advantage.
Hannah Holmes, our Head of People, put it well: "We've been working hard to build an environment where expectations are high, accountability is clear, and people feel genuinely supported. This recognition tells us that work is landing in the right way."
CEO Ben Booth sees it as central to how we run the business: "Building a high-performing culture isn't a side project for us. We believe that getting our people strategy right is what enables us to serve our customers well and grow sustainably."
Being listed among the UK's most thriving places to work is something the whole team has earned, and it reflects the kind of company we're committed to being as we continue to grow.
Want to be part of it?
We're hiring. If you're looking for a place where the culture is real, not just a slide in an onboarding deck, take a look at our open roles.
Blog
5 min read
After-call work isn’t an efficiency problem- it’s a trust problem.
After-call work isn't just a time drain - it's a trust problem. Discover how inconsistent CRM records erode customer loyalty, and how AI-generated call summaries close the loop.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
Ask a contact centre leader about after-call work and they'll usually frame it as a time problem. Wrap time is too long. Agents aren't “going available” quickly enough. AHT is inflating. The fix, in most conversations, is operational: better templates, tighter ACW targets, more monitoring.
That framing is not wrong, but it is incomplete. After-call work is not just a time problem. It’s a quality problem, one which has a direct customer-facing cost that most operations are not measuring.
What actually happens when the call ends
The call ends. The agent is under pressure to “go ready” and be available for the next call in the queue. They have notes to write, a CRM record to update, a disposition to log. Often with multiple systems to update. They have approximately two minutes to do all of that before the queue moves. So, they write what they can. A sentence, maybe two. A shorthand that makes sense to them right now but will mean nothing to the agent who picks up next week's call. Sometimes nothing at all, and a disposition code carries the entire context of a complex interaction. Now multiply that across your team. Ten agents handling the same call type will leave ten different records. Some thorough, some minimal. Some missing the most important detail entirely - what was promised, what was escalated, what the customer was told to expect next. This is the quality problem, and it compounds quietly.
The customer pays for it twice
The first cost is visible: longer calls, higher AHT, agents unavailable for longer than they should be. This is what gets measured. The second cost is less visible but more damaging. The customer calls back. A different agent picks up. They open the record - and it tells them almost nothing useful. So, they ask the customer to explain themselves again. That moment - the repetition, the sense that the company was not paying attention - is where trust erodes. It’s not dramatic. It does not show up immediately in CSAT. But it accumulates, and eventually it becomes the reason a customer switches.
Our Voice of the UK Consumer 2026 research found that 42% of UK consumers have already switched provider due to poor contact centre experience. The word ‘already’ matters. These are not consumers who are at risk of switching – they’ve already left. The post-call gap is not just an internal inefficiency. It's a retention risk dressed up as an admin problem.
Why training cannot fix this
The instinct, when notes are inconsistent, is to retrain. Set clearer standards. Remind agents what a good record looks like. Monitor more closely. This rarely works. Not because agents do not want to do it well, but because the system is not set up to support consistency at pace. An agent writing notes under queue pressure, with no template and no structure, will produce exactly what the conditions allow. Varying quality, varying detail, varying usefulness. The problem is not discipline or intent. It is that the task is being done manually in the least forgiving conditions possible.
What changes when AI writes the notes
Agent Wrap Up Summary generates a structured call record automatically the moment the call ends; drawing on the conversation to produce a consistent summary of what was discussed, what was agreed, and what happens next. Every call. Every agent. Every time.
Consistency is the point. Not just the time saving, though that is real: wrap time typically accounts for 15–20% of an agent's working day, and a 50% reduction returns meaningful capacity to productive contact time. For a 50-agent team, that translates to an illustrative annual saving of £175,000: based on 50 agents, 50 calls per day, a 50% reduction in wrap time, and an average fully loaded agent cost of £25,000 per year.
The more significant change is downstream. When every call produces a reliable, structured record, that record becomes the foundation for what the next agent sees before their call begins. Customer History in Contact Hub surfaces that context automatically - so the agent who picks up next week is starting the call informed.
This is how personalisation at scale works. Not by asking agents to memorise histories or search through fragmented notes. By generating a complete record on every call, so context accumulates and becomes genuinely useful over time.
The record is where the loop closes
Agent Wrap Up Summary is the start of a feedback loop, not the end of one. The structured data it generates - consistent, covering 100% of calls - feeds everything downstream.
Conversation Analytics can analyse that data at scale, identifying coaching opportunities, surfacing compliance drift, and enabling AI Call Scoring that cuts QA review time from 30 minutes to approximately 5 minutes per call. Real Time Agent QA (available in Beta Q4 2026), uses it to guide agents in the moment, surfacing compliance prompts, flagging sentiment shifts, and steering conversations towards the outcomes that best records show actually work.
Better calls produce better records. Better records enable better coaching. Better coaching produces better calls. The loop only works when it is closed. And it closes after the call ends.
Start with the audit
You do not need a platform overhaul to find out where you stand. Pull a sample of CRM records from last week. Read them. Ask a simple question: if the next agent had only this record to go on, what would they know? The answer will tell you more about the state of your post-call process than any metric can.
Want to see how Agent Wrap Up Summary works in practice? Download The Assisted Agent - our practical guide to AI-enabled agent assistance across the full call lifecycle. Or if you'd rather see it live: book a demo with the MaxContact team.