Webinar: AI-Enabled Agent Assistance— Wed 20th May [Register now]
Webinar: AI-Enabled Agent Assistance— Wed 20th May [Register now]
MaxContact builds on record year of growth with new VP of Engineering
We’re pleased to announce a key new appointment to our senior team following an unprecedented period of growth!
In 2021 our rapid growth saw us become one of the fastest-growing contact centre specialists in the country. We saw record sales across the year, with a 45% growth in subscription revenue in 2021, while we also doubled our headcount from 30 to 60 staff. We were also named one of the North’s top 50 fastest growing tech companies in the Northern Tech Awards 2021.
Matt Yates joins the business as VP of Engineering to lead the tech team in developing innovative new solutions and create a market-leading customer engagement platform, as well as discovering new areas for business growth. Matt brings over 20 years industry experience growing and developing engineering departments, most notably for Ivanti (formerly AppSense), where he helped grow the company from £20m – £100m in annual revenue in just five years.
Ben Booth, CEO of MaxContact said: “My co-founders and I set up MaxContact because we saw first-hand the frustrations organisations experienced in this industry with solutions over-promising and under-delivering on features, support and resilience. With Matt at the helm of our engineering team, I’m excited to see us develop even more features and technologies that continue to improve the lives of people that interact through engagement platforms.
“We have big dreams to continue our rapid growth and transform the industry in 2022 and beyond and with people like Matt on board, we’ll continue to make the business be a force for good not only for our people and our organisation, but for the wider industry.”
Matt Yates, VP of Engineering at MaxContact, said: “It’s fantastic to be joining MaxContact at such an exciting time for the business. I’m really passionate about using technology to help people find better ways of working, which chimes well with the values at the heart of the business. The team they’ve built is really special and I’m looking forward to bringing my experience in enterprise IT to help continue growing the company into an industry leading scale-up, all by putting people first.”
(() => {
const run = () => {
const rich = document.querySelector('#rich-text');
const toc = document.querySelector('#toc');
if (!rich || !toc) return;
const headings = rich.querySelectorAll('h2');
if (!headings.length) {
toc.style.display = 'none';
return;
}
const slugCounts = Object.create(null);
const slugify = (str) => {
const base = (str || '')
.trim()
.toLowerCase()
.normalize('NFD').replace(/[\u0300-\u036f]/g, '')
.replace(/[^a-z0-9\s-]/g, '')
.replace(/\s+/g, '-')
.replace(/-+/g, '-');
const n = (slugCounts[base] = (slugCounts[base] || 0) + 1);
return base ? (n > 1 ? `${base}-${n}` : base) : `section-${n}`;
};
// Build TOC off-DOM
const frag = document.createDocumentFragment();
for (let i = 0; i < headings.length; i++) {
const h = headings[i];
const text = (h.textContent || '').trim() || `Section ${i + 1}`;
if (!h.id) h.id = slugify(text);
const a = document.createElement('a');
a.href = `#${h.id}`;
a.className = 'content_link is-secondary';
a.dataset.target = h.id;
a.setAttribute('aria-label', text);
const p = document.createElement('p');
p.className = 'text-size-small';
p.textContent = text;
a.appendChild(p);
frag.appendChild(a);
}
// Single DOM update
toc.innerHTML = '';
toc.appendChild(frag);
toc.addEventListener('click', (e) => {
const link = e.target.closest('a.content_link[href^="#"]');
if (!link) return;
e.preventDefault();
const id = link.getAttribute('href').slice(1);
const target = document.getElementById(id);
if (!target) return;
// Only compute layout once
const targetTop = target.getBoundingClientRect().top + window.scrollY;
const finalY = targetTop - 150;
window.scrollTo({ top: finalY, behavior: 'smooth' });
history.replaceState(null, '', `#${id}`);
}, { passive: false });
};
// Webflow-safe “run after everything is ready”
if (window.Webflow && Webflow.push) {
Webflow.push(() => requestAnimationFrame(run));
} else {
document.addEventListener('DOMContentLoaded', () => requestAnimationFrame(run));
}
})();
related articles
you might also like
Our articles and industry insights give you expert perspectives, practical strategies, and the latest trends to help your business connect smarter and perform better.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
Most contact centres review a small fraction of their calls. A QA analyst picks a handful, scores them, flags what went wrong, and then moves on. It feels like it ticks the box for quality assurance. But for Ofcom-regulated telecoms operations and FCA-regulated financial services firms, it’s not enough, and the consequences of getting it wrong have never been higher.
This article explains why call sampling creates compliance exposure, what always-on monitoring looks like in practice, and what to look for when evaluating your current approach.
What is call quality monitoring?
Call quality monitoring is the process of reviewing agent-customer interactions to assess whether they meet your quality, compliance, and performance standards.
It typically covers:
What was said and how the agent handled the conversation
Whether compliance scripts and protocols were followed
How vulnerable customers were identified and managed
Whether the outcome was appropriate for the customer
How performance compares against your scoring framework
When call quality monitoring is done consistently, it gives you a documented evidence-base across every call type, agent, and campaign. But when it’s done poorly or too infrequently, it leaves gaps that regulators are increasingly likely to find before you do.
How do most contact centres currently monitor calls?
Sampling is the typical approach many call centres take to monitoring calls. A QA reviewer listens to a set number of calls per agent per month, scores them against a framework, and feeds the results back into coaching. It is time-consuming work, so let’s break down the numbers.
Example:
A single reviewer handles 50 calls a month at 30 minutes per call.
This amounts to 25 hours of review time.
And it is still only a fraction of the total call volume reviewed.
The problem here is not the effort; it's the coverage. On average, contact centres manually evaluate 5% of calls per week, meaning many QA operations are leaving the majority of interactions unreviewed. This means:
You don’t know whether your agents are consistently identifying vulnerable customers.
You don’t know whether compliance scripts are being followed on the calls you did not pick.
You are not building an evidence bse, only a small sample.
Manual call sampling statistics
FCA Consumer Duty: you need evidence across every interaction, not a snapshot
For debt collection, insurance, and other FCA-regulated contact centres, the stakes are different but the problem is the same. Consumer Duty requires firms to demonstrate they are delivering good outcomes for retail customers, not just on the calls they reviewed, but consistently and measurably across their entire operation.
The FCA has shifted decisively from implementation to enforcement. Regulators are no longer asking whether you have a quality monitoring process. They are asking whether you can prove, with documented evidence, that your agents are handling vulnerable customers correctly, following compliant scripts, and not causing foreseeable consumer harm. And that’s for every call, not just the ones you checked.
A sampling approach does not produce that evidence. It produces a snapshot.
For more on what the FCA now expects from contact centres in financial services and debt collection, see our Consumer Duty guide.
The problem with call sampling: A Summary
Sampling typically covers around 5% of calls per week, leaving the 95% of interactions unreviewed and unverifiable
Compliance drift happens slowly. By the time sampling catches a behaviour, it is already established and harder to coach out
Poor agent behaviour on outbound calls can go undetected long enough to trigger carrier blocking or an FCA flag
Vulnerable customers may not be identified correctly on calls you never reviewed
Good performance goes unrecognised as you cannot replicate what you cannot see
A sample tells you what happened on the calls you chose to review. It does not tell you what is happening in your operation
From sampling to monitoring: what's actually required
Moving from sampling to consistent call monitoring is not simply a matter of reviewing more calls. It requires the right infrastructure in place, and historically, that infrastructure was either too expensive, too time-consuming, or both.
At a minimum, always-on monitoring requires:
Call recording across all interactions, not just selected campaigns or call types
Transcription that converts voice to text accurately enough to be reviewed and searched at scale
A platform that connects recording, transcription, scoring, and reporting in one place rather than across multiple disconnected tools
Without all three, monitoring at scale either falls back on human reviewers (which is where the 25-hours-per-50-calls problem comes back in) or produces data too inconsistent to be useful as a compliance evidence base.
MaxContact's Conversation Analytics brings all of this together in a single platform. Call recording, real-time transcription, and reporting sit alongside each other. This gives your QA team a single place to monitor, review, and evidence what is happening across every interaction, without stitching together multiple tools or managing separate systems.
The reason most contact centres have defaulted to sampling is not because they did not want better coverage. It is because the operational cost of achieving it manually was prohibitive. A team large enough to review every call would cost more than most mid-market operations can justify. But that has changed.
How Conversation Analytics makes always-on monitoring feasible
Conversation Analytics is the platform that makes consistent, always-on call monitoring operationally viable for mid-market contact centres.
Rather than relying on a QA team to manually select, listen to, and score calls, Conversation Analytics connects call recording, transcription, scoring, and reporting in a single platform – automating quality assurance. Every interaction is captured, transcribed, and made reviewable, giving your QA team complete visibility across all call types, all agents, and all campaigns without the resourcing overhead of manual review at scale.
The cost comparison is significant. Replicating meaningful call coverage with human reviewers alone would cost an estimated £14,000 per month in analyst time for a mid-sized contact centre. Conversation Analytics delivers that coverage at a fraction of the cost, freeing your QA team to focus on coaching, calibration, and the complex calls that genuinely need a human eye.
How AI call monitoring surfaces insights faster
AI is what makes the insights from always-on call monitoring actionable rather than overwhelming.
Without AI, full call coverage creates a different problem; more data than a QA team can meaningfully review and act on. AI-powered call monitoring solves that by doing the heavy lifting on routine scoring, so your team's attention goes where it matters most.
Benefit
What it means for your operation
Structured scorecards answered automatically
Every scorecard question is answered using transcript evidence; no manual listening, no reviewer subjectivity.
Transcript-linked evidence
Every score links back to the exact exchange that informed it, giving you a defensible audit trail.
Faster review cycles
Review time drops from 30 minutes to 5 minutes per call, recovering around 4 days of analyst time every month.
Consistent scoring across your entire operation
The same criteria, applied the same way, across every agent, call type, and campaign every time.
Human oversight built in
Your QA team reviews outputs, calibrates scoring, and focuses on complex calls. AI handles the routine. Governance stays with your team.
The result is not just faster QA. It is a more reliable, more defensible evidence base built on every call, not a sample of them.
What to look for in your call quality monitoring approach
Is your evidence transcript-linked? Generic summaries are not a defensible evidence base. Scoring decisions need to be traceable back to what was actually said.
Is your scoring consistent? If different reviewers score the same call differently, your evidence has a credibility problem. Consistent scoring logic applied across all interactions removes that subjectivity.
Does your QA sit within your analytics platform? If scoring, feedback, and reporting live in separate tools, you create friction and risk. Everything should be in the same place.
Is human oversight built in? Your QA team should be able to review, challenge, and calibrate outputs. Always-on monitoring supports human-led governance, it does not replace it.
Are you scoring the right calls? Configurable triggers and criteria by call type, queue, campaign, or outcome, mean your monitoring effort goes where the compliance risk is highest.
The question is not whether you can afford to monitor every call
It is whether you can afford not to.
Ofcom and the FCA have both made clear that evidence of compliance needs to be consistent, documented, and demonstrable. A sampling process may satisfy an internal audit. It is unlikely to satisfy a regulator asking for proof of good outcomes across your entire customer base.
Always-on call quality monitoring closes that gap. It gives your QA team better data, gives your compliance function defensible evidence, and gives your operation a consistent view of what is actually happening on the phones across all calls, rather than just the ones you happened to pick.
Download the UK Contact Centre Regulatory Guide 2025–2027 to see how the FCA and Ofcom compliance obligations facing your sector map to your call monitoring approach and what good evidenced practice looks like in both.
Download
5 min read
What UK Customers Really Want from Contact Centres in 2026
We've just published our Voice of the UK Consumer 2026 report — and the picture it paints for contact centre leaders is both urgent and actionable.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
We surveyed 1,000 UK adults who had interacted with a contact centre in the last 18 months. The findings reveal something that goes beyond wait times, channel preferences, and AI adoption. This year, the biggest barrier to customer contact isn't the interaction itself - it's getting consumers to engage in the first place.
The Numbers Don't Lie: Trust Is Now an Operational Problem
Before we get to what consumers want, we have to address what's getting in the way. Our research reveals a structural trust deficit playing out before a single agent picks up the phone.
69% of UK consumers always or often screen calls from unknown numbers
46% have ignored a message from a legitimate company because they assumed it was a scam
Only 22% strongly agree they can tell when unexpected company contact is genuine
77% of those who ignored a legitimate call experienced a real consequence such as a missed appointment, an unresolved problem, a missed payment deadline
This is the Trust Gap: the growing distance between a company's confidence in its own outbound contact and what consumers actually believe when they see an unknown number. It affects every sector with outbound ambitions and it can't be fixed by dialling more.
Call Avoidance Varies Dramatically by Sector
Not all sectors face the same screening wall. Our data shows stark differences in call avoidance rates, and the gap between best and worst performing sectors is significant.
Loans, credit and debt management companies are the most avoided, with 37% of consumers saying they'd be least likely to answer a call from this sector. Insurance follows at 25%, with telecoms, technology, and retail/e-commerce close behind at 22–23%. Banks and building societies fare better at 16% avoidance, and notably, they also hold the highest sector trust score at 96%.
The lesson? Trust and answer rates move together. Sectors that have invested in consumer trust over time are reaping the operational benefits in their outbound performance. Those that haven't are paying the price at the identification gate.
"This data should make every contact centre leader pause," says Ben Booth, CEO of MaxContact. "Consumers broadly trust the sectors they deal with, but that trust doesn't translate into picking up the phone. If consumers can't tell the difference between a legitimate call and a scam, outbound strategies will struggle to deliver."
What Actually Makes Consumers Pick Up
The good news is that the Trust Gap is closable. When we asked consumers what would make them more likely to answer, two things stood out clearly:
82% say they would be more likely to answer if caller ID clearly identified the company name
80.5% say a pre-call text or email would make them more likely to pick up
These aren't aspirational preferences - they're operational levers. The problem isn't the dialler. It's the identification gate. Legitimate contact centres aren't losing the persuasion game. They're often not getting on the pitch.
Contact centres should prioritise:
Branded caller ID and carrier number reputation management - so consumers can recognise your call before they decide whether to answer
Pre-call communication - give consumers a reason to expect your call, especially in high-avoidance sectors
Treating contact frequency as a trust variable -too-frequent contact doesn't just frustrate consumers; in regulated sectors, it carries compliance risk
AI Is Here — But Transparency Is Non-Negotiable
UK consumers have been interacting with AI in contact centres for some time. The problem is, many didn't know it.
87% of consumers believe they've interacted with AI or automation in a recent company contact. Of those, 22% were sure or fairly sure they'd been talking to AI — but weren't aware of it at the time. That's more than one in five consumers who discovered, after the fact, that part of their experience was automated.
Nearly 9 in 10 (88%) consumers say it's important for companies to clearly disclose when AI is being used. Half say it's very important.
"The reputational risk of undisclosed AI is real and avoidable," says Ben Booth. "Consumers aren't opposed to AI - they're opposed to being kept in the dark about it. Deploying AI without disclosure doesn't just frustrate customers; it reinforces the same uncertainty that's causing them to screen your calls."
AI Adoption: Where It Works and Where It Doesn't
Consumer opinion on AI is nuanced. Where AI genuinely adds value, consumers are broadly willing to accept it:
Answering FAQs: 36%
Routing to the right department: 35%
Account updates and billing information: 26%
But the picture reverses sharply when it comes to high-stakes interactions. Over half (54%) say they don't want AI involved in emergency situations. Significant numbers also object to AI involvement in complex account problems (50%), financial discussions (49%) and when negotiating terms (46%).
Crucially, 71% of consumers say they'd be comfortable with AI helping resolve an issue faster — as long as a human agent was available throughout. The acceptance of AI is conditional on a clear, accessible escalation path.
Humans Still Matter Where It Counts
Despite the growth of AI and automation, consumers are clear about when they need a person:
Emergency situations - 41% want a human agent
Complex account queries - 33%
Financial discussions — 29%
Explaining a sensitive or personal matter - 26%
Making a complaint - 23%
These aren't edge cases. An AI that handles a billing query well creates modest goodwill. An AI that mishandles a bereavement disclosure or an emergency can permanently damage a customer relationship.
When things go wrong and complaints happen, consumers care most about: a clear explanation of the outcome (39%), being kept updated throughout (37%), appropriate compensation when the company is at fault (33%), and only having to explain the issue once (31%).
What Builds and Breaks Consumer Trust
Our research shows consistent patterns in what drives contact experience, positively and negatively.
What puts consumers off before they even try:
Long wait times: 36%
Being transferred multiple times: 34%
Difficulty reaching a human: 29%
Having to repeat themselves: 28%
What good looks like:
Quick resolution -36%
Easy access to a human when needed - 35%
Knowledgeable agents - 34%
Clear communication throughout - 32%
On channel trust, email remains the most trusted channel for company contact (51%), followed by phone calls (30%) and letters (27%). For outbound communications that don't need an immediate response, email is still the most credible messenger.
Five Focus Areas for Contact Centre Leaders in 2026
Based on our findings, these are the areas that will have the most impact:
Fix the identification gate: Deploy branded caller ID, carrier number reputation management and pre-call communication. The recoverable opportunity isn't every screened call; it's the willing contacts who are filtering themselves out because they fear scams.
Make AI disclosure the default: Clearly disclose AI use at the start of every AI-assisted interaction. In regulated sectors, it's a compliance requirement. Everywhere else, the reputational risk is reason enough.
Protect the human escalation path : Across every question about AI in this study, the most-cited condition for consumer acceptance was the same: a human must be available and clearly signposted. Design the escalation as carefully as you design the AI.
Treat 'only explain once' as an infrastructure target: CRM integration, context-passing between channels, and warm handoffs are the operational response to the number one complaint driver.
Audit complaint journeys against what consumers actually need : A clear outcome explanation, ongoing updates, appropriate compensation, not having to repeat themselves, and a human presence. These five things determine whether a resolved complaint becomes a trust-builder or a churn trigger.
Want the full picture? The Voice of the UK Consumer 2026 report includes sector-by-sector breakdowns across utilities, telecoms, finance/debt, and insurance — with data on vulnerability handling, AI comfort, complaint experience, and regulatory risk. Download the full report here.
Blog
5 min read
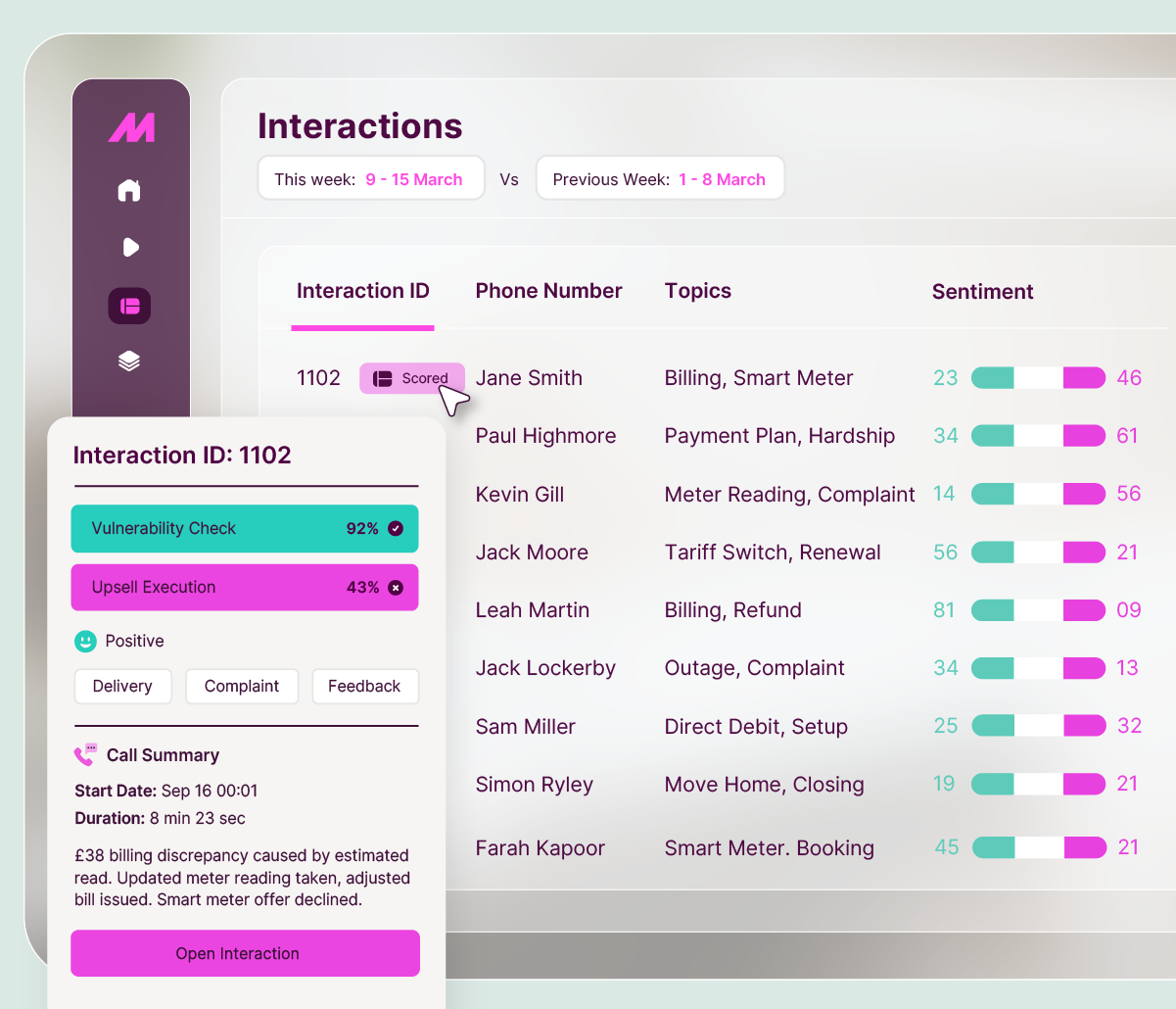
Make Call Reviews Faster, Fairer, and Evidence Backed.
Introducing AI Call Scoring — now included within Conversation Analytics at no additional cost.
(() => {
const WORDS_PER_MINUTE = 200;
const MULTIPLIER = 1; // your choice
const estimateMinutes = (el) => {
if (!el) return null;
const text = (el.innerText || el.textContent || "").trim();
if (!text) return 1;
const words = (text.match(/\S+/g) || []).length;
const baseMinutes = Math.max(1, Math.ceil(words / WORDS_PER_MINUTE));
return Math.max(1, Math.ceil(baseMinutes * MULTIPLIER));
};
const findNearestTargetInItem = (itemRoot, rt) => {
if (!itemRoot) return null;
return itemRoot.querySelector('.is-text');
};
const applyWithin = (root) => {
// More forgiving selector: attribute present or equals "true"
root.querySelectorAll('[data-rich-text], [data-rich-text="true"]').forEach((rt) => {
const itemRoot =
rt.closest('[role="listitem"]') ||
rt.closest('.w-dyn-item') ||
rt.parentElement ||
root;
const target = findNearestTargetInItem(itemRoot, rt);
if (!target) return;
const mins = estimateMinutes(rt);
if (mins != null) target.textContent = `${mins} MIN READ`;
});
};
const init = () => {
applyWithin(document);
// Re-apply on dynamic changes (pagination/filters)
const mo = new MutationObserver((mutations) => {
for (const m of mutations) {
for (const n of m.addedNodes) {
if (!(n instanceof Element)) continue;
if (
n.matches('[data-rich-text], [data-rich-text="true"], [role="list"], .w-dyn-items, .w-dyn-item') ||
n.querySelector?.('[data-rich-text], [data-rich-text="true"]')
) {
applyWithin(n);
}
}
}
});
mo.observe(document.body, { childList: true, subtree: true });
};
// Robust bootstrapping
if (window.Webflow && Array.isArray(window.Webflow)) {
window.Webflow.push(init);
} else if (document.readyState === 'loading') {
document.addEventListener('DOMContentLoaded', init, { once: true });
} else {
// DOM is already ready; run now
init();
}
})();
Here’s a number worth sitting with: 30 minutes.
That's how long it takes to manually score one call. Listen back, fill in the scorecard, write up the notes, log the result. Do that 50 times a month and you've lost on average 4 days per reviewer to scoring alone.
Most QA teams know this. They're not slow or inefficient - the maths just doesn't work. One reviewer for every 25 agents, 30 minutes a call, finite hours in the week. Something must give, and that’s coverage. The industry average sits at around 5% of calls reviewed, which means 95% of what happens on your contact centre floor stays invisible.
Not just to your QA team. To your compliance records. To your coaching programme. To the agents who deserve consistent, fair feedback on every call they handle.
That's the problem AI Call Scoring is built to fix.
Your standards applied to every call you wish to score.
The way it works is straightforward. You define your existing QA standards - built around your business rules, your compliance requirements, your definition of what a good call looks like. AI Call Scoring applies them to your selected calls, scoring each one against your criteria using evidence taken directly from the transcript.
No algorithm deciding what good looks like on your behalf. You set the standard.
What this means for your QA team day to day
One of the things that doesn't get talked about enough in QA is how demoralising inconsistency is. Two reviewers score the same call differently. An agent pushes back. The process loses credibility. And meanwhile, the team is so buried in manual scoring that the actual coaching - the conversations that change behaviour -never happen.
AI Call Scoring brings review time down from around 30 minutes to about 5 minutes per call. Your QA team stop being a scoring machine and start doing what they're good at - calibrating standards, making judgment calls, and coaching agents to improve.
For a reviewer handling 50 calls a month, that's roughly four days back every month. That's a lot of coaching time that wasn't there before.
It's not just for big teams
This is worth saying clearly because it matters: AI Call Scoring isn't just a tool for large operations with dedicated QA departments.
For teams of 50 or more agents, the time savings are significant - around 133 days per year across four QA staff, worth approximately £15k in team time. But beyond the hours, scoring more calls consistently means you start seeing the patterns that a small sample will never show you.
For smaller teams of 10 to 30 agents, it's even more of a shift. Structured QA without dedicated headcount. Team leaders reviewing scored calls in minutes. Compliance coverage that doesn't require a compliance team. And a framework that grows with the business.
When compliance is non-negotiable
For contact centres operating in regulated sectors, the stakes have risen. Consumer Duty, now actively enforced by the FCA, places a direct obligation on organisations to evidence that customers are receiving good outcomes.
When a complaint lands, you can't point to a sample. You need evidence that the specific interaction was handled correctly. AI Call Scoring gives you an auditable record of every scored call, with auto-fail rules that catch compliance breaches - a missed disclosure, an incomplete ID check - regardless of how the rest of the call went. Every call you score is evidenced, auditable and defensible.
Your team stays in control
We want to be clear about this: AI Call Scoring is there to support your QA team, not sideline them. Every scored result can be reviewed, edited, challenged or discarded. Your people stay in the loop. The AI does the volume work - your team does the thinking.
It all lives inside Conversation Analytics — scored calls, common objections, objection handling effectiveness, top performers and saved compliance views, together in one place.
Already on Conversation Analytics? It's yours.
AI Call Scoring is included within Conversation Analytics at no extra cost. If you're already using the suite, it's available to you now.
This is also just the start. Automated QA at Scale is coming later this year - fully automated scoring across campaigns at volume. More on that soon.



.png)

.png)


.png)